VISÃO GERAL
Proxmox VE e VMware oferecem plataformas de virtualização concorrentes. Proxmox VE é um produto corporativo que utiliza QEMU e KVM. VMware ESXi é um produto comercial construído a partir de software proprietário.
Este artigo técnico compara o desempenho do Proxmox VE 7.2 e do VMware ESXi 7.0 Update 3c para aplicações dominadas pelo armazenamento. Os experimentos foram conduzidos em configurações de hardware idênticas operando sob carga moderada a pesada. Os testes se concentram no desempenho agregado de armazenamento de 32 máquinas virtuais ativas simultaneamente.
Nosso sistema de teste é um Dell PowerEdge R7515 com um Processador AMD EPYC 7452 de 32 núcleos e rede Mellanox 100Gbit. O servidor está configurado para inicialização dupla: Proxmox VE 7.2 e ESXi 7.0 Update 3c. O armazenamento está conectado em rede usando NVMe/TCP. O software de armazenamento de backend é o Blockbridge 6.
O banco de testes consiste em 32 máquinas virtuais Ubuntu operando em um único host, cada uma configurada com quatro CPUs virtuais. Um único disco virtual está anexado a cada máquina virtual para teste. Cada máquina virtual opera como um trabalhador fio; os testes são executados simultaneamente em todas as 32 máquinas virtuais. Para cada profundidade de fila e tamanho de bloco, é coletado um ponto de dados que representa o desempenho médio durante um intervalo de 20 minutos imediatamente após um período de aquecimento de 1 minuto.
COMPARAÇÃO DE ARQUITETURA
VMware / PVSCSI / VMFS
A VMware apresenta armazenamento para convidados via controladores SCSI, SATA ou NVMe virtualizados. Tipicamente, o armazenamento é um disco SCSI virtual apresentado usando um Adaptador SCSI Paravirtual VMware. O armazenamento de suporte associado a esses discos virtuais geralmente é um arquivo armazenado em um sistema de arquivos de cluster de propósito especial chamado VMFS. VMFS fornece recursos de gerenciamento de armazenamento, incluindo provisionamento fino, snapshots e mobilidade de cluster.
Nota: VVOLs e Mapeamentos de Dispositivos Raw oferecem um caminho mais direto, mas não são suportados para dispositivos NVMeOF.
O diagrama abaixo ilustra o fluxo de uma E/S emitida por um convidado. Observe que o stack de armazenamento existente é fortemente centrado em SCSI. Dispositivos NVMe se encaixam neste modelo usando uma fina camada de virtualização SCSI, referida como “shim” no diagrama.
CONVIDADO │ ┌────────┐ │ │ PVSCSI │ │ │ DRIVER │ ▼ └┬───────┘ KERNEL │ │ ┌▼───────┐ ┌────────┐ ┌─────────┐ ┌────────┐ │ │ PVSCSI ├──► VMFS ├──► I/O ├──► SCSI │ │ │ DEVICE │ │ │ │ SCHED │ │ DISK │ │ └────────┘ └────────┘ └─────────┘ └┬───────┘ │ │ │ ┌▼───────┐ ┌────────┐ ┌────────┐ │ │ HPP ├──► SCSI ├──► NVME │ │ │ │ │ PATH │ │ SHIM │ │ └────────┘ └────────┘ └┬───────┘ │ │ │ ┌▼───────┐ ┌────────┐ │ │ NVME ├──► NVME │ │ │ CORE │ │ TCP │ ▼ └────────┘ └────────┘Nossa experiência sugere que o escalonador centralizado de E/S é um gargalo significativo e fonte de latência. Felizmente, o NVMe/TCP usa o plugin mais recente "High-Performance Plugin" (ou seja, HPP) por padrão. O plugin HPP permite que as E/S do convidado ignorem o escalonador, desde que o armazenamento de backend permaneça rápido. Dica: Os umbrais de latência para ignorar o escalonador de E/S são configurados da seguinte forma:esxcli storage core device latencythreshold set -t [valor em milissegundos]. Mais informações estão disponíveis aqui
Proxmox VE / Virtio-SCSI / RAW
Proxmox VE normalmente apresenta armazenamento para convidados como dispositivos SCSI virtualizados conectados a um controlador SCSI virtual implementado usando virtio-scsi. Quando usado com armazenamento conectado em rede, os dispositivos SCSI virtuais do convidado são suportados por dispositivos de bloco Linux nativos; não há camada de sistema de arquivos de cluster intermediária no Proxmox VE. Provisionamento fino, snapshots, criptografia e alta disponibilidade são implementados pelo armazenamento conectado em rede.
O diagrama abaixo ilustra o fluxo de uma E/S emitida por um convidado. Observe que os domínios de agendamento são bastante diferentes entre Proxmox VE e VMware. O Proxmox VE agendaa E/S para dispositivos individuais, e os dispositivos NVMe usam o agendador no-op do Linux. A VMware agenda E/S para VMs concorrentes, tentando coordenar o uso eficiente das capacidades de fila de E/S de um dispositivo físico.
Nota: Fomos cuidadosos para garantir que a profundidade de fila agregada não fosse um fator limitante de desempenho.
CONVIDADO
│ ┌─────────────┐
│ │ VIRTIO-SCSI │
│ │ DRIVER │
▼ └┬────────────┘
QEMU │
│ ┌▼────────────┐ ┌─────────┐
│ │ VIRTIO-SCSI ├───► ASYNC │
│ │ DEVICE │ │ I/O │
▼ └─────────────┘ └┬────────┘
KERNEL │
│ ┌▼────────┐ ┌─────────┐
│ │ BLOCK ├──► SCHED │
│ │ LAYER │ │ NOOP │
│ └─────────┘ └┬────────┘
│ │
│ ┌▼────────┐ ┌─────────┐
│ │ NVME ├──► NVME │
│ │ CORE │ │ TCP │
▼ └─────────┘ └─────────┘RESULTADOS
Proxmox VE Oferece Mais IOPS
Proxmox VE superou o VMware ESXi em 56 de 57 testes, proporcionando ganhos de desempenho de IOPS de quase 50%. Os ganhos máximos em casos de teste individuais com grandes profundidades de fila e tamanhos de E/S pequenos excedem 70%.
O gráfico abaixo mostra os ganhos percentuais (média em todos os tamanhos de bloco) para cada profundidade de fila. Por exemplo, o ponto de dados QD=128 é o ganho médio medido para os tamanhos de bloco de .5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB e 128KiB em uma profundidade de fila de 128. O gráfico mostra uma vantagem média de desempenho de 48,9% a favor do Proxmox VE.

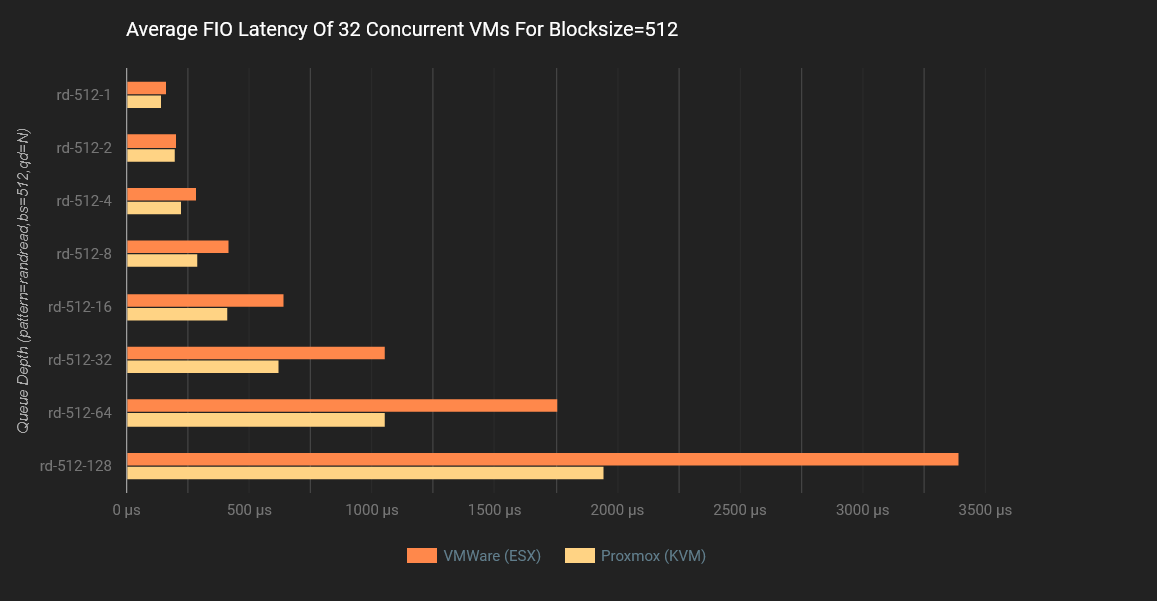
Proxmox VE Possui Menor Latência
O Proxmox VE reduziu a latência em mais de 30% ao mesmo tempo em que ofereceu maior IOPS, superando o VMware em 56 de 57 testes.
O gráfico abaixo mostra a redução de latência (média em todos os tamanhos de bloco) para cada profundidade de fila. Por exemplo, o ponto de dados QD=128 é a redução média de latência para os tamanhos de bloco de .5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB e 128KiB em uma profundidade de fila de 128. O gráfico mostra uma vantagem de desempenho de 32,6% a favor do Proxmox VE.

Proxmox VE Fornece Mais Largura de Banda
O Proxmox VE alcançou 38% a mais de largura de banda do que o VMware ESXi durante condições de carga de pico: 12,8GB/s para Proxmox VE versus 9,3GB/s para VMware ESXi.
AVALIAÇÕES
IOPS
Os seguintes gráficos de IOPS plotam o desempenho relativo do Proxmox VE e do VMware ESXi. Cada gráfico apresenta resultados médios de IOPS para oito profundidades de fila diferentes operando em tamanho de bloco fixo. Os resultados são apresentados para sete tamanhos de bloco, incluindo .5K, 4K, 8K, 16K, 32K, 64K e 128K. Resultados mais altos de IOPS são melhores.






LARGURA DE BANDA
Os gráficos de largura de banda plotam o throughput médio de dados medido durante os testes de IOPS para Proxmox VE e VMware. Cada gráfico mostra a largura de banda média para oito profundidades de fila operando em tamanho de bloco fixo. Os resultados são apresentados para sete tamanhos de bloco, incluindo .5K, 4K, 8K, 16K, 32K, 64K e 128K. Maior largura de banda é melhor.






LARGURA DE BANDA
Os gráficos de largura de banda plotam o throughput médio de dados medido durante os testes de IOPS para Proxmox VE e VMware. Cada gráfico mostra a largura de banda média para oito profundidades de fila operando em tamanho de bloco fixo. Os resultados são apresentados para sete tamanhos de bloco, incluindo .5K, 4K, 8K, 16K, 32K, 64K e 128K. Maior largura de banda é melhor.



COMPARAÇÕES RELATIVAS
MELHORIA DE IOPS
Os gráficos na seção a seguir apresentam o ganho ou perda percentual de IOPS associado ao uso do Proxmox VE em vez do VMware ESXi. Um valor positivo indica que o Proxmox VE alcança mais IOPS. Um valor negativo indica que o Proxmox VE alcança menos IOPS.







MÉDIA DE MELHORIA DE IOPS
O gráfico abaixo mostra a porcentagem média de IOPS para todos os tamanhos de bloco em cada profundidade de fila. Por exemplo, o ponto de dados QD=128 é o ganho médio medido para os tamanhos de bloco de .5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB e 128KiB. O gráfico mostra uma vantagem média de desempenho de 48,9% a favor do Proxmox VE.

REDUÇÃO MÉDIA DE LATÊNCIA
O gráfico abaixo mostra a redução média de latência para todos os tamanhos de bloco em cada profundidade de fila. Por exemplo, o ponto de dados QD=128 é a redução média de latência para os tamanhos de bloco de .5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB e 128KiB. O gráfico mostra uma vantagem de desempenho de 32,6% a favor do Proxmox VE.

AMBIENTE VMWARE
Diagrama de Rede
┌──────────────────────────────┐ ┌─────────────────────┐
│ ┌────┐ | ┌───────────────┐ | │
│ ┌────┐ | ESXi 7.0-U3C │── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ BLOCKBRIDGE 6.X │
│ ┌────┐ | | 100G DUAL PORT │ └───────────────┘ │ QUAD ENGINE │
│ │ 32 │ |─┘ X16 GEN3 │ ┌───────────────┐ │ 2X 100G DUAL PORT │
│ │ VM │─┘ 32 CORE AMD |── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ 4M IOPS / 25 GB/s │
| └────┘ | └───────────────┘ | |
└──────────────────────────────┘ └─────────────────────┘
Descrição
VMware ESXi 7.0 Update 3c está instalado em um Dell PowerEdge R7515 com um processador AMD EPYC 7452 32-Core, 512GB de RAM e um único adaptador de rede de porta dupla Mellanox de 100Gbit. O adaptador Mellanox é um dispositivo x16 Gen3 com um throughput máximo de 126Gbit/s (limitado pela conectividade PCIe). O processador AMD está funcionando com NPS=4 e sem hyperthreading.
Trinta e duas máquinas virtuais estão provisionadas no host. Cada VM está instalada com Ubuntu 22.04.01 LTS, executando a versão do kernel Linux 5.15.0-1018-kvm. As VMs têm quatro CPUs virtuais e 4GB de RAM. O overcommit de CPU lógica é de 4:1 (128 CPUs virtuais provisionadas em um processador de 32 núcleos). Cada VM tem um dispositivo de bloco de inicialização contendo o sistema de arquivos raiz e um dispositivo de teste separado.
Para maximizar o desempenho e distribuir uniformemente a carga, foram utilizados quatro datastore VMFS6. Cada datastore foi suportado por um único dispositivo NVMe/TCP, cada um em uma engine de plano de dados Blockbridge diferente. Foram usadas configurações padrão para multipath, pares de filas de E/S e profundidade de fila. Observamos que o VMware abriu oito pares de filas por caminho de armazenamento, para uma profundidade de fila lógica combinada de 4096 IOs.
Em cada VM, o fio-3.28 é executado no modo “servidor”. Usamos um nó de controle externo para coordenar as execuções de benchmark entre as VMs.
Nossa suíte de testes consiste em 56 cargas de trabalho de I/O diferentes. Cada suíte contém tamanhos de bloco e profundidades de fila variáveis. Cada carga de trabalho consiste em um aquecimento de 1 minuto e um período de medição de 20 minutos. Cada suíte leva 19,6 horas para ser concluída. Uma descrição de carga de trabalho de exemplo aparece abaixo:
$ cat read-rand-bs4096-qd32.fio
[global]
rw=randread
direct=1
ioengine=libaio
time_based=1
runtime=1200
ramp_time=60
numjobs=1
[sdb]
filename=/dev/sdb
bs=4096
iodepth=32
Ajustes Necessários
Requisições Pendentes
O ESXi possui uma configuração especial que controla a profundidade da fila de E/S do dispositivo para um convidado quando outros convidados estão acessando o mesmo dispositivo de armazenamento. Em versões anteriores do ESXi, isso era feito por meio do parâmetro global Disk.SchedNumReqOutstanding. A partir da versão 5.5, o controle foi relegado a um parâmetro apenas do esxcli. Dado que estamos executando benchmarking de máquinas concorrentes operando com alta profundidade de fila, é essencial ajustar os padrões.
esxcli storage core device set --sched-num-req-outstanding 1024 -dBypass do Agendador de E/S
Por padrão, o ESXi passa todas as E/S por um agendador de E/S. Este agendador cria filas internas, que são altamente ineficientes com dispositivos de armazenamento de alta velocidade.
Configurar o limite sensível à latência permite que o VMware ignore o agendador de E/S, enviando E/S diretamente do PSA (ou seja, Pluggable Storage Architecture) para o HPP (ou seja, High-Performance Plugin). Esse bypass oferece um impulso perceptível de desempenho para NVMe/TCP, que aproveita nativamente o HPP para seleção de caminho de múltiplos caminhos e pares de filas de E/S.
esxcli storage core device latencythreshold set -v 'NVMe' -m 'Blockbridge' -t 10Software
Versão VMware
Produto: VMware ESXi
Versão: 7.0.3
Compilação: Releasebuild-19035710
Atualização: 3
Patch: 20Versão Blockbridge
versão: 6.1.0
lançamento: 6667.1
compilação: 4056
Versão do Convidado
Distribuidor ID: Ubuntu
Descrição: Ubuntu 22.04.1 LTS
Lançamento: 22.04
Codinome: jammy
Hardware
Plataforma do Servidor
Informações do sistema
Fabricante: Dell Inc.
Nome do Produto: PowerEdge R7515
Processador
memorySize = 549330464768,
cpuModel = "AMD EPYC 7452 32-Core Processor ",
cpuMhz = 2346,
numCpuPkgs = 1,
numCpuCores = 32,
numCpuThreads = 32,
numNics = 6,
numHBAs = 19Configuração NUMA do Processador
Arquitetura: x86_64
Modo de operação da CPU(s): 32-bit, 64-bit
Ordem dos Bytes: Little Endian
Tamanhos de endereço: 43 bits físico, 48 bits virtual
CPU(s): 32
Lista de CPU(s) On-line: 0-31
Thread(s) por núcleo: 1
Núcleo(s) por soquete: 32
Soquete(s): 1
Node(s) NUMA: 4
ID do Fornecedor: AuthenticAMD
Família da CPU: 23
Modelo: 49
Nome do Modelo: AMD EPYC 7452 32-Core Processor
Stepping: 0
CPU MHz: 3139.938
BogoMIPS: 4690.89
Virtualização: AMD-V
Cache L1d: 1 MiB
Cache L1i: 1 MiB
Cache L2: 16 MiB
Cache L3: 128 MiB
CPU(s) do Nó NUMA0: 0-7
CPU(s) do Nó NUMA1: 8-15
CPU(s) do Nó NUMA2: 16-23
CPU(s) do Nó NUMA3: 24-31Adaptador de Rede & Conexão
Nome Driver Estado da Conexão Velocidade MTU Descrição
------ ---------- ----------------- ------ ---- -----------
vmnic0 ntg3 Ativo 1000 1500 Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet
vmnic1 ntg3 Ativo 1000 1500 Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet
vmnic2 nmlx5_core Ativo 100000 9000 Mellanox Technologies 100GbE dual-port QSFP28 (MCX516A-CCAT)
vmnic3 nmlx5_core Ativo 100000 9000 Mellanox Technologies 100GbE dual-port QSFP28 (MCX516A-CCAT)Configurações de Coalescência de Interrupção do Adaptador de Rede
NIC RX microseconds RX maximum frames TX microseconds TX Maximum frames Adaptive RX Adaptive TX
------ --------------- ----------------- --------------- ----------------- ----------- -----------
vmnic0 18 15 72 53 Desativado Desativado
vmnic1 18 15 72 53 Desativado Desativado
vmnic2 3 64 16 32 Ativado Desativado
vmnic3 3 64 16 32 Ativado Desativado
AMBIENTE PROXMOX VE
Diagrama de Rede
┌──────────────────────────────┐ ┌─────────────────────┐
│ ┌────┐ | ┌───────────────┐ | │
│ ┌────┐ | Proxmox 7.2 │── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ BLOCKBRIDGE 6.X │
│ ┌────┐ | | 100G DUAL PORT │ └───────────────┘ │ QUAD ENGINE │
│ │ 32 │ |─┘ X16 GEN3 │ ┌───────────────┐ │ 2X 100G DUAL PORT │
│ │ VM │─┘ 32 CORE AMD |── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ 4M IOPS / 25 GB/s │
| └────┘ | └───────────────┘ | |
└──────────────────────────────┘ └─────────────────────┘
Descrição
Proxmox VE 7.2 (versão do kernel 5.15.53-1-pve) está instalado em um Dell PowerEdge R7515 com um processador AMD EPYC 7452 de 32 núcleos, 512GB de RAM e um adaptador de rede Mellanox de porta dupla de 100Gbit. O adaptador Mellanox é um dispositivo x16 Gen3 com uma taxa de transferência máxima de 126Gbit/s (limitada pela conectividade PCIe). O processador AMD está operando com NPS=4 e sem hiper-threading.
Trinta e duas máquinas virtuais estão provisionadas no host. Cada VM está instalada com Ubuntu 22.04.01 LTS, executando a versão do kernel Linux 5.15.0-1018-kvm. As VMs têm quatro CPUs virtuais e 4GB de RAM. O compromisso lógico da CPU é de 4:1 (128 CPUs virtuais provisionadas em um processador de 32 núcleos).
Em cada VM, o fio-3.28 é executado no modo “servidor”. Usamos um nó de controle externo para coordenar as execuções dos benchmarks entre as VMs.
Cada VM possui um dispositivo de bloco de inicialização contendo o sistema de arquivos raiz separado do armazenamento em teste. Para cada VM, provisionamos armazenamento usando pvesm alloc e o conectamos à VM com qm set. Antes de cada execução de teste, as VMs são reinicializadas para garantir consistência.
Nosso conjunto de testes consiste em 56 cargas de trabalho de E/S diferentes. Cada conjunto contém tamanhos de bloco e profundidades de fila variáveis. Cada carga de trabalho consiste em um período de aquecimento de 1 minuto e um período de medição de 20 minutos. Cada conjunto leva 19,6 horas para ser concluído. Uma descrição de carga de trabalho de exemplo aparece abaixo:
$ cat read-rand-bs4096-qd32.fio
[global]
rw=randread
direct=1
ioengine=libaio
time_based=1
runtime=1200
ramp_time=60
numjobs=1
[sdb]
filename=/dev/sdb
bs=4096
iodepth=32Ajustes Necessários
Nenhum parâmetro de ajuste foi necessário.
Software
Versão do Proxmox VE
# pveversion
pve-manager/7.2-7/d0dd0e85 (kernel em execução: 5.15.53-1-pve)Versão do Blockbridge
versão: 6.1.0
release: 6667.1
build: 4056Versão do Hóspede
ID do Distribuidor: Ubuntu
Descrição: Ubuntu 22.04.1 LTS
Lançamento: 22.04
Codinome: jammyHardware
Plataforma do Servidor
Informações do Sistema
Fabricante: Dell Inc.
Nome do Produto: PowerEdge R7515Processador
Processador: 32 x AMD EPYC 7452 32-Core Processor (1 Soquete)
Versão do Kernel: Linux 5.15.53-1-pve #1 SMP PVE 5.15.53-1 (Sex, 26 Ago 2022 16:53:52 +0200)
Versão do Gerenciador PVE pve-manager/7.2-7/d0
dd0eConfiguração NUMA do Processador
Arquitetura: x86_64
Modo(s) de operação da CPU: 32-bit, 64-bit
Ordem dos Bytes: Little Endian
Tamanhos de Endereço: 43 bits físicos, 48 bits virtuais
CPU(s): 32
Lista de CPU(s) online: 0-31
Thread(s) por núcleo: 1
Núcleo(s) por soquete: 32
Soquete(s): 1
Nó(s) NUMA: 4
ID do Fornecedor: AuthenticAMD
Família da CPU: 23
Modelo: 49
Nome do Modelo: AMD EPYC 7452 32-Core Processor
Stepping: 0
MHz da CPU: 3139.938
BogoMIPS: 4690.89
Virtualização: AMD-V
Cache L1d: 1 MiB
Cache L1i: 1 MiB
Cache L2: 16 MiB
Cache L3: 128 MiB
CPU(s) do nó NUMA0: 0-7
CPU(s) do nó NUMA1: 8-15
CPU(s) do nó NUMA2: 16-23
CPU(s) do nó NUMA3: 24-31Adaptador de Rede
Controlador Ethernet: Mellanox Technologies MT27800 Family [ConnectX-5]
Subsistema: Mellanox Technologies Mellanox ConnectX®-5 MCX516A-CCAT
Flags: mestre de barramento, devsel rápido, latência 0, IRQ 624, nó NUMA 1, grupo IOMMU 89
Memória em ac000000 (64 bits, pré-carregável) [tamanho=32M]
Expansão ROM em ab100000 [desativada] [tamanho=1M]
Driver do kernel em uso: mlx5_core
Módulos do kernel: mlx5_coreConectividade PCI do Adaptador de Rede
[ 3.341416] mlx5_core 0000:41:00.0: versão do firmware: 16.26.1040
[ 3.341456] mlx5_core 0000:41:00.0: largura de banda PCIe disponível de 126.016 Gb/s (link PCIe x16 8.0 GT/s)
[ 3.638556] mlx5_core 0000:41:00.0: Limite de taxa: 127 taxas são suportadas, faixa: 0Mbps a 97656Mbps
[ 3.638597] mlx5_core 0000:41:00.0: E-Switch: Total de portas virtuais 4, por porta virtual: uc máx(1024) mc máx(16384)
[ 3.641492] mlx5_core 0000:41:00.0: Evento de módulo de porta: módulo 0, Cabo conectadoLink do Adaptador de Rede
Quadro de pausa anunciado: Simétrico
Negociação automática anunciada: Sim
Modos FEC anunciados: Nenhum RS BASER
Modos de link anunciados pelo parceiro: Não reportado
Quadro de pausa anunciado pelo parceiro: Não
Negociação automática anunciada pelo parceiro: Sim
Modos FEC anunciados pelo parceiro: Não reportado
Velocidade: 100000Mb/s
Duplex: Completo
Negociação automática: ativado
Porta: Cobre de Anexo Direto
PHYAD: 0
Transceptor: interno
Suporta Wake-on: d
Wake-on: d
Nível de mensagem atual: 0x00000004 (4)
link
Link detectado: simConfigurações de Coalescência de Interrupção do Adaptador de Rede
Adaptativo RX: ligado TX: ligado
stats-block-usecs: n/a
intervalo de amostra: n/a
taxa de pacotes baixa: n/a
taxa de pacotes alta: n/a
rx-usecs: 8
rx-frames: 128
rx-usecs-irq: n/a
rx-frames-irq: n/a
tx-usecs: 8
tx-frames: 128
tx-usecs-irq: n/a
tx-frames-irq: n/aRECURSOS ADICIONAIS
Disponível em:  Português
Português English (Inglês)
English (Inglês) Español (Espanhol)
Español (Espanhol)