VISIÓN GENERAL
Proxmox VE y VMware ofrecen plataformas de virtualización competitivas. Proxmox VE es un producto empresarial que aprovecha QEMU y KVM. VMware ESXi es un producto comercial construido a partir de software propietario.
Esta nota técnica compara el rendimiento de Proxmox VE 7.2 y VMware ESXi 7.0 Update 3c para aplicaciones dominadas por el almacenamiento. Se realizaron experimentos en configuraciones de hardware idénticas que operan bajo carga moderada a pesada. Las pruebas se centran en el rendimiento de almacenamiento agregado de 32 máquinas virtuales activas concurrentemente.
Nuestro sistema de prueba es un Dell PowerEdge R7515 con un procesador AMD EPYC 7452 de 32 núcleos y una red Mellanox de 100 Gbit. El servidor está configurado para arranque dual: Proxmox VE 7.2 y ESXi 7.0 Update 3c. El almacenamiento está conectado en red utilizando NVMe/TCP. El software de almacenamiento backend es Blockbridge 6.
El banco de pruebas consiste en 32 máquinas virtuales Ubuntu que operan en un solo host, cada una configurada con cuatro CPUs virtuales. Se adjunta un solo disco virtual a cada máquina virtual para realizar pruebas. Cada máquina virtual opera como un trabajador fio; las pruebas se ejecutan concurrentemente en las 32 máquinas virtuales. Para cada profundidad de cola y tamaño de bloque, se recopila un punto de datos que representa el rendimiento promedio durante un intervalo de 20 minutos inmediatamente después de un período de calentamiento de 1 minuto.
COMPARACIÓN DE ARQUITECTURA
VMware / PVSCSI / VMFS
VMware presenta almacenamiento a los huéspedes a través de controladores virtualizados SCSI, SATA o NVMe. Normalmente, el almacenamiento es un disco SCSI virtual presentado utilizando un Adaptador SCSI Paravirtual de VMware. El almacenamiento de respaldo asociado con estos discos virtuales es generalmente un archivo almacenado en un sistema de archivos de clúster de propósito especial llamado VMFS. VMFS proporciona características de gestión de almacenamiento, incluida la aprovisionamiento delgado, instantáneas y movilidad de clúster.
Nota: VVOLs y asignaciones de dispositivos en bruto ofrecen un camino más directo pero no son compatibles con dispositivos NVMeOF.
El diagrama a continuación ilustra el flujo de un E/S emitida por un huésped. Tenga en cuenta que la pila de almacenamiento existente se centra en gran medida en SCSI. Los dispositivos NVMe encajan en este modelo utilizando una fina capa de virtualización SCSI, referida como “shim” en el diagrama.
HUÉSPED │ ┌────────┐ │ │ PVSCSI │ │ │ CONTROLADOR │ ▼ └┬───────┘ KERNEL │ │ ┌▼───────┐ ┌────────┐ ┌─────────┐ ┌────────┐ │ │ PVSCSI ├──► VMFS ├──► E/S ├──► SCSI │ │ │ DEV │ │ │ │ PROGRAM │ │ DISCO │ │ └────────┘ └────────┘ └─────────┘ └┬───────┘ │ │ │ ┌▼───────┐ ┌────────┐ ┌────────┐ │ │ HPP ├──► SCSI ├──► NVME │ │ │ │ │ RUTA │ │ SHIM │ │ └────────┘ └────────┘ └┬───────┘ │ │ │ ┌▼───────┐ ┌────────┐ │ │ NVME ├──► NVME │ │ │ NÚCLEO │ │ TCP │ ▼ └────────┘ └────────┘Nuestra experiencia sugiere que el programador de E/S centralizado es un cuello de botella significativo y una fuente de latencia. Afortunadamente, NVMe/TCP utiliza el complemento "High-Performance Plugin" (es decir, HPP) por defecto. El complemento HPP permite a las E/S de los huéspedes omitir el programador siempre que el almacenamiento de respaldo siga siendo rápido. Consejo: Los umbrales de latencia para omitir el programador de E/S se configuran de la siguiente manera:esxcli storage core device latencythreshold set -t [valor en milisegundos]. Más información está disponible aquí
Proxmox VE / Virtio-SCSI / RAW
Proxmox VE presenta típicamente almacenamiento a los huéspedes como dispositivos SCSI virtualizados conectados a un controlador SCSI virtual implementado utilizando virtio-scsi. Cuando se utiliza con almacenamiento conectado en red, los dispositivos SCSI virtuales del huésped están respaldados por dispositivos de bloques nativos de Linux; no hay una capa de sistema de archivos de clúster intermedio en Proxmox VE. La provisión delgada, las instantáneas, el cifrado y la alta disponibilidad se implementan mediante el almacenamiento conectado en red.
El diagrama a continuación ilustra el flujo de una E/S emitida por un huésped. Tenga en cuenta que los dominios de programación son notablemente diferentes entre Proxmox VE y VMware. Proxmox VE programa E/S para dispositivos individuales, y los dispositivos NVMe utilizan el programador no-op de Linux. VMware programa E/S para máquinas virtuales competidoras, tratando de coordinar el uso eficiente de las capacidades de encolado de E/S de un dispositivo físico.
Nota: Nos aseguramos de que la profundidad de cola agregada no fuera un factor limitante del rendimiento.
HUÉSPED
│ ┌─────────────┐
│ │ VIRTIO-SCSI │
│ │ DRIVER │
▼ └┬────────────┘
QEMU │
│ ┌▼────────────┐ ┌─────────┐
│ │ VIRTIO-SCSI ├───► ASYNC │
│ │ DISPOSITIVO │ │ E/S │
▼ └─────────────┘ └┬────────┘
KERNEL │
│ ┌▼────────┐ ┌─────────┐
│ │ BLOQUEO ├──► PROGRAMACIÓN │
│ │ CAPA │ │ NOOP │
│ └─────────┘ └┬────────┘
│ │
│ ┌▼────────┐ ┌─────────┐
│ │ NVME ├──► NVME │
│ │ NÚCLEO │ │ TCP │
▼ └─────────┘ └─────────┘RESULTADOS
Proxmox VE Ofrece Más IOPS
Proxmox VE superó a VMware ESXi en 56 de 57 pruebas, ofreciendo ganancias de rendimiento en IOPS de casi el 50%. Las ganancias máximas en casos de prueba individuales con grandes profundidades de cola y tamaños de E/S pequeños superan el 70%.
El gráfico a continuación muestra las ganancias porcentuales (promediadas en tamaños de bloque) para cada profundidad de cola. Por ejemplo, el punto de datos QD=128 es la ganancia promedio medida para los tamaños de bloque de 0,5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB y 128KiB en una profundidad de cola de 128. El gráfico muestra una ventaja de rendimiento promedio del 48,9% a favor de Proxmox VE.

Proxmox VE Tiene Menor Latencia
Proxmox VE redujo la latencia en más del 30% mientras entregaba IOPS más altos simultáneamente, superando a VMware en 56 de 57 pruebas.
El gráfico a continuación muestra la reducción de latencia (promediada en tamaños de bloque) para cada profundidad de cola. Por ejemplo, el punto de datos QD=128 es la reducción promedio en la latencia para los tamaños de bloque de 0,5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB y 128KiB en una profundidad de cola de 128. El gráfico muestra una ventaja de rendimiento del 32,6% a favor de Proxmox VE.

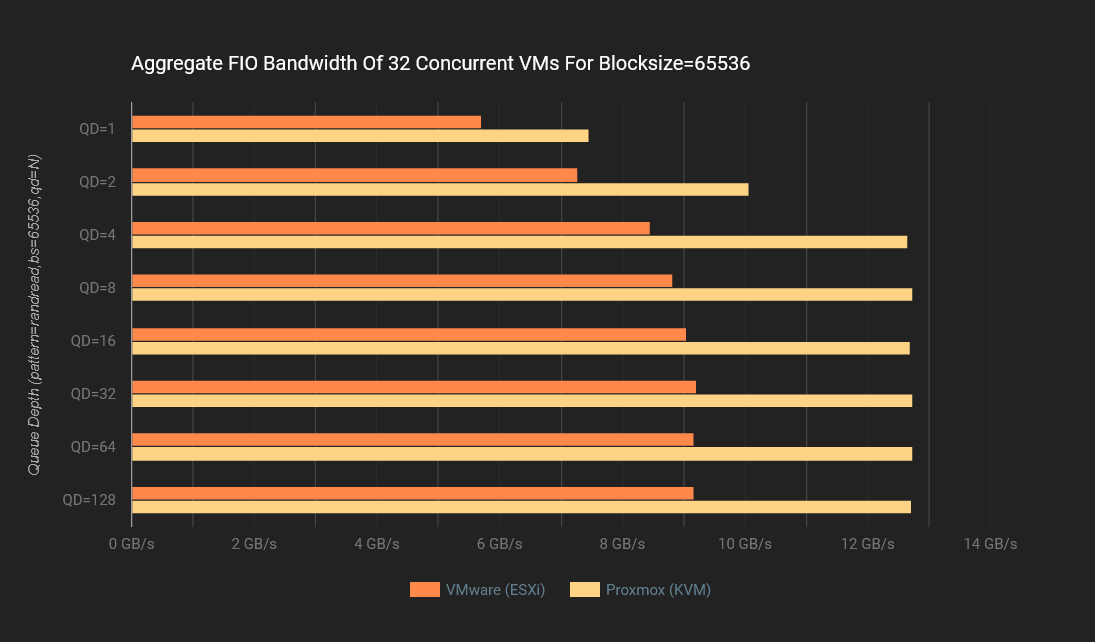
Proxmox VE Ofrece Más Ancho de Banda
Proxmox VE logró un ancho de banda un 38% más alto que VMware ESXi durante condiciones de carga máxima: 12,8 GB/s para Proxmox VE versus 9,3 GB/s para VMware ESXi.
PRUEBAS DE REFERENCIA
IOPS
Las siguientes gráficas de IOPS representan el rendimiento relativo de Proxmox VE y VMware ESXi. Cada gráfico presenta los resultados de IOPS promedio para ocho profundidades de cola diferentes operando con un tamaño de bloque fijo. Los resultados se presentan para siete tamaños de bloque, incluidos 0,5K, 4K, 8K, 16K, 32K, 64K y 128K. Resultados de IOPS más altos son mejores






ANCHO DE BANDA
Las gráficas de ancho de banda representan el rendimiento promedio de datos medido durante las pruebas de IOPS para Proxmox VE y VMware. Cada gráfico muestra el ancho de banda promedio para ocho profundidades de cola operando con un tamaño de bloque fijo. Los resultados se presentan para siete tamaños de bloque, incluidos 0,5K, 4K, 8K, 16K, 32K, 64K y 128K. Un ancho de banda más alto es mejor.






ANCHO DE BANDA
Las gráficas de ancho de banda representan el rendimiento promedio de datos medido durante las pruebas de IOPS para Proxmox VE y VMware. Cada gráfico muestra el ancho de banda promedio para ocho profundidades de cola operando con un tamaño de bloque fijo. Los resultados se presentan para siete tamaños de bloque, incluidos 0,5K, 4K, 8K, 16K, 32K, 64K y 128K. Un ancho de banda más alto es mejor.




COMPARACIONES RELATIVAS
MEJORA DE IOPS
Las gráficas en la siguiente sección presentan el porcentaje de ganancia o pérdida en IOPS asociado con el uso de Proxmox VE en lugar de VMware ESXi. Un valor positivo indica que Proxmox VE logra más IOPS. Un valor negativo indica que Proxmox VE logra menos IOPS.







Mejora Promedio de IOPS
El gráfico a continuación muestra el porcentaje promedio de IOPS para todos los tamaños de bloque en cada profundidad de cola. Por ejemplo, el punto de datos QD=128 es la ganancia promedio medida para los tamaños de bloque de 0.5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB y 128KiB. El gráfico muestra una ventaja de rendimiento promedio del 48.9% a favor de Proxmox VE.

Reducción Promedio de Latencia
El gráfico a continuación muestra la reducción promedio de latencia para todos los tamaños de bloque en cada profundidad de cola. Por ejemplo, el punto de datos QD=128 es la reducción promedio de latencia para los tamaños de bloque de 0.5KiB, 4KiB, 8KiB, 16KiB, 32KiB, 64KiB y 128KiB. El gráfico muestra una ventaja de rendimiento del 32.6% a favor de Proxmox VE.

Entorno de VMware
Diagrama de Red
┌──────────────────────────────┐ ┌─────────────────────┐
│ ┌────┐ | ┌───────────────┐ | │
│ ┌────┐ | ESXi 7.0-U3C │── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ BLOCKBRIDGE 6.X │
│ ┌────┐ | | 100G DUAL PORT │ └───────────────┘ │ QUAD ENGINE │
│ │ 32 │ |─┘ X16 GEN3 │ ┌───────────────┐ │ 2X 100G DUAL PORT │
│ │ VM │─┘ 32 CORE AMD |── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ 4M IOPS / 25 GB/s │
| └────┘ | └───────────────┘ | |
└──────────────────────────────┘ └─────────────────────┘
Descripción
VMware ESXi 7.0 Update 3c está instalado en un Dell PowerEdge R7515 con un procesador AMD EPYC 7452 de 32 núcleos, 512GB de RAM y un adaptador de red Mellanox de doble puerto de 100Gbit. El adaptador Mellanox es un dispositivo x16 Gen3 con un rendimiento máximo de 126Gbit/s (limitado por la conectividad PCIe). El procesador AMD se está ejecutando con NPS=4 y sin hyperthreading.
Treinta y dos máquinas virtuales están aprovisionadas en el host. Cada VM está instalada con Ubuntu 22.04.01 LTS, ejecutando la versión del kernel Linux 5.15.0-1018-kvm. Las VM tienen cuatro CPUs virtuales y 4GB de RAM. El sobrecompromiso lógico de la CPU es de 4:1 (128 VCPUs provisionadas en un procesador de 32 núcleos). Cada VM tiene un dispositivo de arranque que contiene el sistema de archivos raíz y un dispositivo de prueba separado.
Para maximizar el rendimiento y distribuir uniformemente la carga, se utilizaron cuatro almacenes de datos VMFS6. Cada almacén de datos estaba respaldado por un solo dispositivo NVMe/TCP, cada uno en un motor de datos Blockbridge diferente. Se utilizaron configuraciones predeterminadas para el multipath, pares de cola de E/S y profundidad de cola. Observamos que VMware abrió ocho pares de cola por ruta de almacenamiento, para una profundidad de cola lógica combinada de 4096 E/S.
En cada VM, fio-3.28 se ejecuta en modo “servidor”. Usamos un nodo controlador externo para coordinar las ejecuciones de las pruebas en las VM.
Nuestro conjunto de pruebas consiste en 56 cargas de trabajo de E/S diferentes. Cada conjunto contiene diferentes tamaños de bloque y profundidades de cola. Cada carga de trabajo consiste en un periodo de calentamiento de 1 minuto y un periodo de medición de 20 minutos. Cada conjunto tarda 19.6 horas en completarse. A continuación, se muestra una descripción de una carga de trabajo de muestra:
$ cat read-rand-bs4096-qd32.fio
[global]
rw=randread
direct=1
ioengine=libaio
time_based=1
runtime=1200
ramp_time=60
numjobs=1
[sdb]
filename=/dev/sdb
bs=4096
iodepth=32
Ajustes Necesarios
Solicitudes Pendientes
ESXi tiene un ajuste especial que controla la profundidad de la cola de E/S del dispositivo para un huésped cuando otros huéspedes están accediendo al mismo dispositivo de almacenamiento. En versiones anteriores de ESXi, esto se realizaba a través del parámetro global Disk.SchedNumReqOutstanding. A partir de la versión 5.5, el control ha sido relegado a un parámetro solo disponible a través de esxcli. Dado que estamos ejecutando pruebas de benchmarking de máquinas concurrentes operando con una alta profundidad de cola, es esencial ajustar los valores predeterminados.
esxcli storage core device set --sched-num-req-outstanding 1024 -dBypass del Planificador de E/S
Por defecto, ESXi pasa cada E/S a través de un planificador de E/S. Este planificador crea colas internas, lo cual es altamente ineficiente con dispositivos de almacenamiento de alta velocidad.
Establecer el umbral sensible a la latencia permite a VMware evitar el planificador de E/S, enviando E/S directamente desde el PSA (es decir, Arquitectura de Almacenamiento Enchufable) al HPP (es decir, Complemento de Alto Rendimiento). Este bypass ofrece un impulso notable al rendimiento para NVMe/TCP, que aprovecha nativamente el HPP para la selección de multipath y pares de colas de E/S.
esxcli storage core device latencythreshold set -v 'NVMe' -m 'Blockbridge' -t 10Software
Versión de VMware
Producto: VMware ESXi
Versión: 7.0.3
Compilación: Releasebuild-19035710
Actualización: 3
Parche: 20Versión de Blockbridge
versión: 6.1.0
lanzamiento: 6667.1
compilación: 4056
Versión del Huésped
ID de Distribuidor: Ubuntu
Descripción: Ubuntu 22.04.1 LTS
Versión: 22.04
Nombre en clave: jammy
Hardware
Plataforma del Servidor
Información del Sistema
Fabricante: Dell Inc.
Nombre del Producto: PowerEdge R7515
Procesador
tamaño de la memoria = 549330464768,
modelo de CPU = "AMD EPYC 7452 32-Core Processor ",
MHz de CPU = 2346,
numCpuPkgs = 1,
numCpuCores = 32,
numCpuThreads = 32,
numNics = 6,
numHBAs = 19Configuración NUMA del Procesador
Arquitectura: x86_64
Modo de operación de CPU(s): 32 bits, 64 bits
Orden de bytes: Little Endian
Tamaños de dirección: 43 bits físicos, 48 bits virtuales
CPU(s): 32
Lista de CPU(s) en línea: 0-31
Hilo(s) por núcleo: 1
Núcleo(s) por zócalo: 32
Zócalo(s): 1
Nodo(s) NUMA: 4
ID del vendedor: AuthenticAMD
Familia de la CPU: 23
Modelo: 49
Nombre del modelo: AMD EPYC 7452 32-Core Processor
Paso: 0
MHz de CPU: 3139.938
BogoMIPS: 4690.89
Virtualización: AMD-V
Caché L1d: 1 MiB
Caché L1i: 1 MiB
Caché L2: 16 MiB
Caché L3: 128 MiB
CPU(s) del nodo NUMA0: 0-7
CPU(s) del nodo NUMA1: 8-15
CPU(s) del nodo NUMA2: 16-23
CPU(s) del nodo NUMA3: 24-31Adaptador de Red & Enlace
Nombre Controlador Estado del Enlace Velocidad MTU Descripción
------ ---------- ----------- ------ ---- -----------
vmnic0 ntg3 Activo 1000 1500 Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet
vmnic1 ntg3 Activo 1000 1500
Broadcom Corporation NetXtreme BCM5720 Gigabit Ethernet
vmnic2 nmlx5_core Activo 100000 9000 Mellanox Technologies 100GbE dual-port QSFP28 (MCX516A-CCAT)
vmnic3 nmlx5_core Activo 100000 9000 Mellanox Technologies 100GbE dual-port QSFP28 (MCX516A-CCAT)Ajustes de Coalescencia de Interrupción del Adaptador de Red
NIC RX microsegundos RX máximo de tramas TX microsegundos TX Máximo de tramas RX Adaptativo TX Adaptativo
------ --------------- ----------------- --------------- ----------------- ----------- -----------
vmnic0 18 15 72 53 Desactivado Desactivado
vmnic1 18 15 72 53 Desactivado Desactivado
vmnic2 3 64 16 32 Activado Desactivado
vmnic3 3 64 16 32 Activado Desactivado
Entorno de Proxmox VE
Diagrama de Red
┌──────────────────────────────┐ ┌─────────────────────┐
│ ┌────┐ | ┌───────────────┐ | │
│ ┌────┐ | Proxmox 7.2 │── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ BLOCKBRIDGE 6.X │
│ ┌────┐ | | 100G DUAL PORT │ └───────────────┘ │ QUAD ENGINE │
│ │ 32 │ |─┘ X16 GEN3 │ ┌───────────────┐ │ 2X 100G DUAL PORT │
│ │ VM │─┘ 32 CORE AMD |── NVME/TCP ─┤ SN2100 - 100G ├──────── ┤ 4M IOPS / 25 GB/s │
| └────┘ | └───────────────┘ | |
└──────────────────────────────┘ └─────────────────────┘
Descripción
Proxmox VE 7.2 (versión del kernel 5.15.53-1-pve) está instalado en un Dell PowerEdge R7515 con un procesador AMD EPYC 7452 de 32 núcleos, 512 GB de RAM y un adaptador de red Mellanox de doble puerto de 100 Gbit. El adaptador Mellanox es un dispositivo x16 Gen3 con un rendimiento máximo de 126 Gbit/s (limitado por la conectividad PCIe). El procesador AMD está funcionando con NPS=4 y sin hiperprocesamiento.
Treinta y dos máquinas virtuales están provisionadas en el host. Cada VM está instalada con Ubuntu 22.04.01 LTS, ejecutando la versión del kernel de Linux 5.15.0-1018-kvm. Las VM tienen cuatro CPUs virtuales y 4 GB de RAM. El sobrecompromiso lógico de la CPU es de 4:1 (128 CPUs virtuales provisionadas ejecutándose en un procesador de 32 núcleos).
En cada VM, fio-3.28 se ejecuta en modo “servidor”. Utilizamos un nodo de control externo para coordinar las ejecuciones de prueba en todas las VM.
Cada VM tiene un dispositivo de bloque de arranque que contiene el sistema de archivos raíz separado del almacenamiento en prueba. Para cada VM, provisionamos almacenamiento utilizando pvesm alloc y lo adjuntamos a la VM con qm set. Antes de cada ejecución de prueba, las VM se reinician para garantizar la consistencia.
Nuestro conjunto de pruebas consta de 56 cargas de trabajo de E/S diferentes. Cada conjunto contiene tamaños de bloque y profundidades de cola variables. Cada carga de trabajo consta de un calentamiento de 1 minuto y un período de medición de 20 minutos. Cada conjunto tarda 19.6 horas en completarse. A continuación, se muestra una descripción de una carga de trabajo de muestra:
$ cat read-rand-bs4096-qd32.fio
[global]
rw=randread
direct=1
ioengine=libaio
time_based=1
runtime=1200
ramp_time=60
numjobs=1
[sdb]
filename=/dev/sdb
bs=4096
iodepth=32Ajustes Necesarios
No se requirieron parámetros de ajuste.
Software
Versión de Proxmox VE
# pveversion
pve-manager/7.2-7/d0dd0e85 (kernel en ejecución: 5.15.53-1-pve)Versión de Blockbridge
versión: 6.1.0
lanzamiento: 6667.1
compilación: 4056Versión del Huésped
ID de Distribuidor: Ubuntu
Descripción: Ubuntu 22.04.1 LTS
Versión: 22.04
Nombre en clave: jammyHardware
Plataforma del Servidor
Información del Sistema
Proveedor: Dell Inc.
Nombre del Producto: PowerEdge R7515Procesador
Procesador: 32 x AMD EPYC 7452 32-Core Processor (1 Socket)
Versión del Kernel: Linux 5.15.53-1-pve #1 SMP PVE 5.15.53-1 (Fri, 26 Aug 2022 16:53:52 +0200)
Versión del Administrador PVE pve-manager/7.2-7/d0dd0eConfiguración NUMA del Procesador
Arquitectura: x86_64
Modo de operación de CPU(s): 32 bits, 64 bits
Orden de bytes: Little Endian
Tamaños de dirección: 43 bits físicos, 48 bits virtuales
CPU(s): 32
Lista de CPU(s) en línea: 0-31
Hilo(s) por núcleo: 1
Núcleo(s) por zócalo: 32
Zócalo(s): 1
Nodo(s) NUMA: 4
ID del vendedor: AuthenticAMD
Familia de la CPU: 23
Modelo: 49
Nombre del modelo: AMD EPYC 7452 32-Core Processor
Paso: 0
MHz de CPU: 3139.938
BogoMIPS: 4690.89
Virtualización: AMD-V
Caché L1d: 1 MiB
Caché L1i: 1 MiB
Caché L2: 16 MiB
Caché L3: 128 MiB
CPU(s) del nodo NUMA0: 0-7
CPU(s) del nodo NUMA1: 8-15
CPU(s) del nodo NUMA2: 16-23
CPU(s) del nodo NUMA3: 24-31Adaptador de Red
Controlador Ethernet: Mellanox Technologies MT27800 Family [ConnectX-5]
Subsistema: Mellanox Technologies Mellanox ConnectX®-5 MCX516A-CCAT
Flags: bus master, fast devsel, latency 0, IRQ 624, Nodo NUMA 1, grupo IOMMU 89
Memoria en ac000000 (64 bits, prefetchable) [tamaño=32M]
Expansión ROM en ab100000 [deshabilitado] [tamaño=1M]
Controlador de kernel en uso: mlx5_core
Módulos de kernel: mlx5_coreConectividad PCI del Adaptador de Red
[ 3.341416] mlx5_core 0000:41:00.0: versión del firmware: 16.26.1040
[ 3.341456] mlx5_core 0000:41:00.0: ancho de banda PCIe disponible de 126.016 Gb/s (enlace PCIe x16 de 8.0 GT/s)
[ 3.638556] mlx5_core 0000:41:00.0: Límite de velocidad: Se admiten 127 velocidades, rango: de 0 Mbps a 97656 Mbps
[ 3.638597] mlx5_core 0000:41:00.0: E-Switch: Total de puertos virtuales 4, por puerto virtual: máx. uc(1024) máx. mc(16384)
[ 3.641492] mlx5_core 0000:41:00.0: Evento del módulo del puerto: módulo 0, Cable conectadoEnlace del Adaptador de Red
Uso de marcos de pausa anunciados: Sí
Negociación automática anunciada: Sí
Modos FEC anunciados: Ninguno RS BASER
Modos de enlace anunciados por el compañero de enlace: No reportado
Uso de marcos de pausa anunciados por el compañero de enlace: No
Negociación automática anunciada por el compañero de enlace: Sí
Modos FEC anunciados por el compañero de enlace: No reportado
Velocidad: 100000Mb/s
Duplex: Completo
Negociación automática: activada
Puerto: Conexión Directa de Cobre
PHYAD: 0
Transceptor: interno
Soporta Despertar: d
Despertar: d
Nivel de mensaje actual: 0x00000004 (4)
enlace
Enlace detectado: síConfiguración de Coalescencia de Interrupción del Adaptador de Red
RX Adaptativo: activado TX: activado
Estadísticas de uso de bloque de muestra: n/d
Intervalo de muestra: n/d
Tasa de paquetes baja: n/d
Tasa de paquetes alta: n/d
rx-usecs: 8
rx-frames: 128
rx-usecs-irq: n/d
rx-frames-irq: n/d
tx-usecs: 8
tx-frames: 128
tx-usecs-irq: n/d
tx-frames-irq: n/dRECURSOS ADICIONALES
Disponível em:  Português (Portugués, Brasil)
Português (Portugués, Brasil) English (Inglés)
English (Inglés) Español
Español